Simultaneous equations model
Simultaneous equation models are a form of statistical model in the form of a set of linear simultaneous equations. They are often used in econometrics.
Contents |
Structural and reduced form
Suppose there are m regression equations of the form
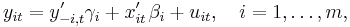
where i is the equation number, and t = 1, …, T is the observation index. In these equations xit is the ki×1 vector of exogenous variables, yit is the dependent variable, y−i,t is the ni×1 vector of all other endogenous variables which enter the ith equation on the right-hand side, and uit are the error terms. The “−i” notation indicates that the vector y−i,t may contain any of the y’s except for yit (since it is already present on the left-hand side). The regression coefficients βi and γi are of dimensions ki×1 and ni×1 correspondingly. Vertically stacking the T observations corresponding to the ith equation, we can write each equation in vector form as
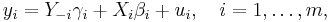
where yi and ui are T×1 vectors, Xi is a T×ki matrix of exogenous regressors, and Y−i is a T×ni matrix of endogenous regressors on the right-hand side of the ith equation. Finally, we can move all endogenous variables to the left-hand side and write the m equations jointly in vector form as
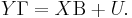
This representation is known as the structural form. In this equation Y = [y1 y2 … ym] is the T×m matrix of dependent variables. Each of the matrices Y−i is in fact an ni-columned submatrix of this Y. The m×m matrix Γ, which describes the relation between the dependent variables, has a complicated structure. It has ones on the diagonal, and all other elements of each column i are either the components of the vector −γi or zeros, depending on which columns of Y were included in the matrix Y−i. The T×k matrix X contains all exogenous regressors from all equations, but without repetitions (that is, matrix X should be of full rank). Thus, each Xi is a ki-columned submatrix of X. Matrix Β has size k×m, and each of its columns consists of the components of vectors βi and zeros, depending on which of the regressors from X were included or excluded from Xi. Finally, U = [u1 u2 … um] is a T×m matrix of the error terms.
Postmultiplying the structural equation by Γ −1, the system can be written in the reduced form as
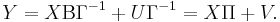
This is already a simple general linear model, and it can be estimated for example by ordinary least squares. Unfortunately, the task of decomposing the estimated matrix 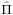 into the individual factors Β and Γ −1 is quite complicated, and therefore the reduced form is more suitable for prediction but not inference.
into the individual factors Β and Γ −1 is quite complicated, and therefore the reduced form is more suitable for prediction but not inference.
Assumptions
Firstly, the rank of the matrix X of exogenous regressors must be equal to k, both in finite samples and in the limit as T → ∞ (this later requirement means that in the limit the expression 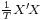 should converge to a nondegenerate k×k matrix). Matrix Γ is also assumed to be non-degenerate.
should converge to a nondegenerate k×k matrix). Matrix Γ is also assumed to be non-degenerate.
Secondly, error terms are assumed to be serially independent and identically distributed. That is, if the tth row of matrix U is denoted by u(t), then the sequence of vectors {u(t)} should be iid, with zero mean and some covariance matrix Σ (which is unknown). In particular, this implies that E[U] = 0, and E[U′U] = T Σ.
Lastly, the identification conditions requires that the number of unknowns in this system of equations should not exceed the number of equations. More specifically, the order condition requires that for each equation ki + ni ≤ k, which can be phrased as “the number of excluded exogenous variables is greater or equal to the number of included endogenous variables”. The rank condition of identifiability is that rank(Πi0) = ni, where Πi0 is a (k − ki)×ni matrix which is obtained from Π by crossing out those columns which correspond to the excluded endogenous variables, and those rows which correspond to the included exogenous variables.
Estimation
Two-stages least squares (2SLS)
The simplest and the most common[1] estimation method for the simultaneous equations model is the so-called two-stage least squares method, developed independently by Theil (1953) and Basmann (1957). It is an equation-by-equation technique, where the endogenous regressors on the right-hand side of each equation are being instrumented with the regressors X from all other equations. The method is called “two-stage” because it conducts estimation in two steps:[2]
- Step 1: Regress Y−i on X and obtain the predicted values
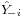 ;
; - Step 2: Estimate γi, βi by the ordinary least squares regression of yi on and Xi.
If the ith equation in the model is written as
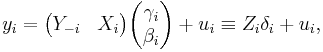
where Zi is a T×(ni + ki) matrix of both endogenous and exogenous regressors in the ith equation, and δi is an (ni + ki)-dimensional vector of regression coefficients, then the 2SLS estimator of δi will be given by[3]
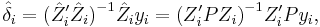
where P = X (X ′X)−1X ′ is the projection matrix onto the linear space spanned by the exogenous regressors X.
Indirect least squares
Indirect least squares is an approach in econometrics where the coefficients in a simultaneous equations model are estimated from the reduced form model using ordinary least squares.[4][5] For this, the structural system of equations is transformed into the reduced form first. Once the coefficients are estimated the model is put back into the structural form.
Limited information maximum likelihood (LIML)
The “limited information” maximum likelihood method was suggested by Anderson & Rubin (1949). The explicit formula for this estimator is:[6]
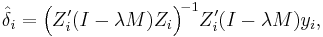
where M = I − X (X ′X)−1X ′, Mi = I − Xi (Xi′Xi)−1Xi′, and λ is the smallest characteristic root of the matrix
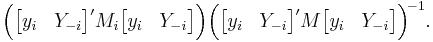
Note that when λ = 1 the LIML estimator coincides with the 2SLS estimator.
Three-stage least squares (3SLS)
The three-stage least squares estimator was introduced by Zellner & Theil (1962). It combines two-stage least squares (2SLS) with seemingly unrelated regressions (SUR).
See also
Notes
- ^ Greene (2003, p. 398)
- ^ Greene (2003, p. 399)
- ^ Greene (2003, p. 399)
- ^ Park, S-B. (1974) "On Indirect Least Squares Estimation of a Simultaneous Equation System", The Canadian Journal of Statistics / La Revue Canadienne de Statistique, 2 (1), 75–82 JSTOR 3314964
- ^ Vajda, S., Valko, P. Godfrey, K.R. (1987) "Direct and indirect least squares methods in continuous-time parameter estimation", Automatica, 23 (6), 707–718 doi:10.1016/0005-1098(87)90027-6
- ^ Amemiya (1985, p. 235)
References
- Amemiya, Takeshi (1985). Advanced econometrics. Cambridge, Massachusetts: Harvard University Press. ISBN 0-674-00560-0.
- Anderson, T.W.; Rubin, H. (1949). "Estimator of the parameters of a single equation in a complete system of stochastic equations". Annals of Mathematical Statistics 20 (1): 46–63. JSTOR 2236803.
- Basmann, R.L. (1957). "A generalized classical method of linear estimation of coefficients in a structural equation". Econometrica 25 (1): 77–83. JSTOR 1907743.
- Davidson, Russell; MacKinnon, James G. (1993). Estimation and inference in econometrics. Oxford University Press. ISBN 978-0-19-506011-9.
- Greene, William H. (2002). Econometric analysis (5th ed.). Prentice Hall. ISBN 0-13-066198-9.
- Zellner, A.; Theil, H. (1962). "Three-stage least squares: simultaneous estimation of simultaneous equations". Econometrica 30 (1): 54–78. JSTOR 1911287.
External links
- About.com:economics Online dictionary of economics, entry for ILS